Кодування символів
АЗБУКА МОРЗЕ

Одним із перших цифрових способів передачі інформації став код Морзе. Код Морзе — це нерівномірний телеграфний код, де спосіб кодування літер алфавіту, цифр та інших символів подано певною комбінацією «крапок» і «тире». За одиницю часу приймається тривалість однієї крапки, тривалість тире дорівнює трьом крапкам, пауза між елементами одного знака — одна крапка, між знаками в слові — 3 крапки, між словами — 7 крапок. Азбука, з якої формується зазначепий код, була названа па честь американського винахідника Семюела Морзе, який придумав її в 1838 році. Телеграф і радіотелеграф спочатку використовували азбуку Морзе, пізніше почали застосовз'вати код Водо та ASCII, які є більш зручними для автоматизації.
КОДУВАННЯ СИМВОЛІВ У КОМП'ЮТЕРНІЙ ТЕХНІЦІ
Символи тексту людина розрізняє за накресленням. Наприклад, кожен з нас швидко визначить у тексті літеру «а», яким би шрифтом її не було набрано. Якщо слідувати аналогії зі сприйняттям тексту людиною, то в комп’ютері потрібно зберігати зображення літер, потім з них складати слова і зберігати зображення рядків.
Зрозуміло, що цей спосіб неефективний, оскільки доведеться зберігати безліч зображень, хоча кількість літер, з яких їх складено, обмежена (це літери алфавіту тої мови, якою подано текст).
Тому для комп’ютерного подання текстової інформації застосовується інший спосіб: символи алфавіту кодуються двійковими числами, а текст подається у вигляді набору чисел — кодів символів, що його складають.
Щоб такий набір чисел можна було декодувати, слід знати, де закінчується і де починається код коленого символу, а для цього, як було показано на прикладі чисел, необхідно перед кодуванням визначити потрібну для кодування кількість розрядів. Толе яку довжину коду символу взяти, щоб закодувати всі символи, які можуть трапитися в тексті?
Якщо це двійковий код з довжиною 2 розряди, то з його допомогою можна б}'де закодувати алфавіт, що містить 4 символи, оскільки за цієї довжини коду існує чотири різні його комбінації. Двійковий код з довжиною З розряди дозволяє закодувати алфавіт, що містить 8 символів (рис. 1.6).
|
Код з довжиною 2 розряди |
||
|
Код |
Літера |
Десяткове значення коду |
|
00 |
А |
0 |
|
01 |
Б |
1 |
|
10 |
В |
2 |
|
11 |
Г |
3 |
|
Код з довжиною 3 розряди |
||
|
Код |
Літера |
Десяткове значення коду |
|
000 |
А |
0 |
|
001 |
Б |
1 |
|
010 |
В |
2 |
|
011 |
Г |
3 |
|
100 |
ґ |
4 |
|
101 |
д |
5 |
|
110 |
Е |
6 |
|
111 |
Є |
7 |
Рис. 1.6. Кодування символів двійковими кодами різної довжини
Прослідковусться така закономірність:
2 розряди — 2 • 2 = 4 = 22 символів;
3 розряди — 2 • 2 • 2 = 8 = 23 символів;
4 розряди — 2 • 2 • 2 • 2 = 32 = 2‘ символів;
N розрядів — 2 • 2 • 2 • ... • 2 • 2 = 2*у символів.
З допомогою двійкового коду завдовжки N розрядів можна закодувати алфавіт, що містить г'^символів.
Таким чином, щоб закодувати текст, слід обрати довжину коду, достатню для кодування потрібної кількості символів, і скласти таблищо, де буде вказано, який код якому символу відповідає. Такі таблиці вже складено, і називають їх наборами символів.
Таблиця 1.3. Символи з розширеного набору символів ASCII та їхні коди
|
Символ |
Десяткове значення коду |
Код |
Символ |
Десяткове значення коду |
Код |
|
пробіл |
32 |
00100000 |
0 |
48 |
00110000 |
|
І |
33 |
00100001 |
1 |
49 |
00110001 |
|
# |
35 |
00100011 |
2 |
50 |
00110010 |
|
$ |
36 |
00100100 |
3 |
51 |
00110011 |
|
* |
42 |
00101010 |
4 |
52 |
00110100 |
|
+ |
43 |
00101011 |
5 |
53 |
00110101 |
|
J |
44 |
00101100 |
6 |
54 |
00110110 |
|
- |
45 |
00101101 |
7 |
55 |
00110111 |
|
. |
46 |
00101110 |
8 |
56 |
00111000 |
|
/ |
47 |
00101111 |
9 |
57 |
00111001 |
|
А |
65 |
01000001 |
N |
78 |
01001110 |
|
В |
66 |
01000010 |
0 |
79 |
01001111 |
|
С |
67 |
01000011 |
р |
80 |
01010000 |
|
D |
68 |
01000100 |
Q |
81 |
01010001 |
|
Е |
69 |
01000101 |
R |
82 |
01010010 |
|
F |
70 |
01000110 |
S |
83 |
01010011 |
|
G |
71 |
01000111 |
т |
84 |
01010100 |
|
Н |
72 |
01001000 |
и |
85 |
01010101 |
|
І |
73 |
01001001 |
V |
86 |
01010110 |
|
J |
74 |
01001010 |
W |
87 |
01010111 |
|
К |
75 |
01001011 |
X |
88 |
01011000 |
|
L |
76 |
01001100 |
Y |
89 |
01011001 |
|
М |
77 |
01001101 |
Z |
90 |
01011010 |
Сьогодні найпоширенішими с набори символів ASCII, Unicode («юпі-код») і сумісні з ними. Фрагмент розширеного набору символів ASCII
наведено в табл. 1.3. У цьому наборі, як ви можете пересвідчитися, для кодування застосовують 8 розрядів. Розмір алфавіту, який можна закодувати з допомогою такого набору, вміщує 256 символів (пронумеровані десятковими цифрами від 0 до 255). Цього достатньо, щоб закодувати цифри, знаки пунктуації, латинські літери (великі й малі) та літери кирилиці (великі й малі).
Недолік такої таблиці кодування — неможливість закодувати текст, що містить фрагменти багатьма мовами, наприклад, англійською (латиниця), українською (кирилиця) і німецькою (латиниця та умляути).
Щоб усунути це обмеження, в 1991 році було запропоновано стандарт кодування Unicode, який дозволяє використовз'вати в текстах будь-які символи будь-яких мов світу. Загалом в Unicode для кодування символів відведено 31 розряд двійкового коду.
Використовуючи Unicode, закодовано всі алфавіти відомих мов, зокрема і «мертвих» (єгипетські ієрогліфи, писемність майя, етруський алфавіт). Для мов, що мають кілька алфавітів або варіантів написання (наприклад, японська, індійська), закодовано всі варіанти. В Unicode внесено всі математичні, хімічні, музичні та інші наукові символьні позначення. Потенційна ємність Unicode така велика, що наразі використов.усться лише незначний відсоток доступних кодів символів.
Перші 128 символів у стандарті Unicode збігаються з таблицею ASCII. Далі розміщено основні алфавіти сучасних мов. Вони містяться в першій частині таблиці, значення їхніх кодів не перевищують 216 = 65536. Тому в с.учаспих комп’ютерах застосовується скорочена 16-розрядпа версія Unicode, яка називається базовою багатомовною площиною (Base Miltilingual Plane, BMP).
ОСОБЛИВОСТІ КОДУВАННЯ КИРИЛИЦІ
У наборі ASCII перші 32 коди (з 0 по 31) відведені для операцій (перенесення рядка, скасування попередньої операції, подавання звукового сигналу). Ці коди мають сприйматися пристроєм виведення як команди.
Наступні коди, з 32 по 127, є інтернаціональними і відповідають символам латинського алфавіту, цифрам, знакам арифметичних операцій та знакам пунктуації. Коди з 128 по 255 — національні, тобто в кодуваннях для різних мов тому самому коду відповідають різні символи.
Для українських і російських літер є кілька кодових таблиць (code pages), що різняться розташуванням символів. Найчастіше вам траплятимуться такі: KOI8-U, KOI8-R, Windows-1251, Code Page 866 (CP 866), ISO 8859. Тексти, створені з використанням однієї таблиці, неправильно
відображаються у разі використання іншої. Саме це с причиною того, що інколи в браузері замість тексту ви бачите беззмістовний набір знаків (рис. 1.7).
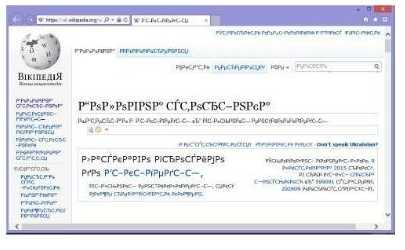
ВПРАВА 2
Рис. 1.7. Символи відображаються неправильно
Завдання. Ознайомитися з особливостями кодування тексту.
1. Запустіть програму Word, виберіть команду для вставлення символів у текст на вкладці Вставлення ► Символ ► Інші символи. Відкриється вікно, показане на рис. 1.8.
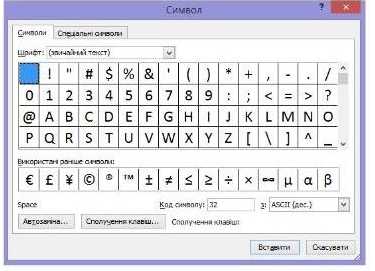
Рис. 1.8. Діалогове вікно для вставлення символів
2. Виберіть у списку Шрифт елемент (звичайний текст), а у списку 2’ елемент ASCII (дес.). Збільште вікно, як показано на рисунку.
3. Зверніть увагу, що у вікні обрано символ пробілу. Його код (32) відображається в нижньому правому куті вікна. Праворуч від поля з кодом розташовано список, у якому обирають таблицю символів і формат відображення значень їхніх кодів (десятковий чи шістнадцятковий).
4. Знайдіть у таблиці та клацніть символ 126 — після нього, окрім, знаків йдуть літери мов, у яких застосовується латиниця (німецька, голландська, фінська). Виберіть у списку таблиць елемент кирилиця (дес.). Набір символів після 126 символу змінився — у таблиці з’явилися літери кирилиці (рис. 1.9).
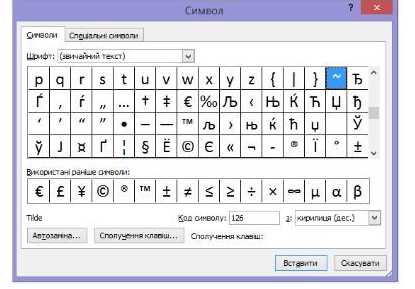
Рис. 1.9. Символи кирилиці в таблиці символів
5. Виберіть у списку з: таблицю Юнікод (шіст.). У верхній частині вікна праворуч з'явиться список Набір. Розгорніть його, ви побачите, які набори символів і літер закодовано в цій таблиці (рис. 1.10).
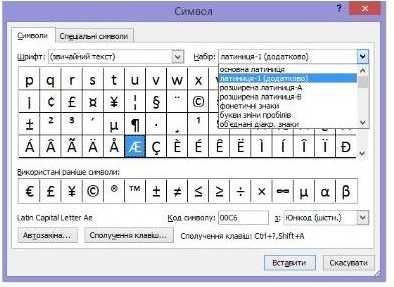
Рис. 1.10. Перелік наборів символів, закодованих у таблиці Юнікод
6. Відкрийте в браузері сторінку uk.wikipedia.org, що містить текст українською мовою. У контекстному меню сторінки виберіть команду Коди-ровка (Кодування) та інше кодування сторінки (наприклад, Западноев-ропейская (ISO)). Як зміниться її текст? Поверніть початкове кодування сторінки, обравши елемент Юникод (UTF-8).
Висновки
Для комп’ютерного подання текстової інформації символи алфавіту кодуються двійковими числами, а текст подасться у вигляді набору чисел — кодів символів, що його складають.
З допомогою двійкового коду з довжиною N розрядів можна закодувати алфавіт, що містить 2Л символів.
Для кодування тексту створено таблиці, в яких вказано, який код якому символу відповідає, їх називають наборами символів.
Найпоширенішими с набори символів ASCII, Unicode та сумісні з ними.
Контрольні запитання та завдання
1. Який підхід до кодування запропонував свого часу Семюел Морзе?
2. Який підхід застосовано до кодування текстової інформації в комп’ютерних технологіях?
3. Яку назву мас стандартний набір, що складається з 256 символів?
4. Яку назву мас стандарт кодування, що дозволяє здійснити кодування всіх алфавітів відомих мов?
5. Чому па веб-сторіиці може неправильно відображатися текст?
Питання для роздумів
1°. Яку мінімальну довжину коду матиме повідомлення, подане за допомогою алфавіту з 65 символів?
2°. Чому азбука Морзе с нерівномірним кодом?
Завдання для досліджень
1. Підготуйте повідомлення про використання на практиці різних способів кодування текстової інформації.
2. Дізнайтеся, що таке стенографія і яке її призначення.
Це матеріал з підручника Інформатика 8 клас Казанцева
Автор: admin от 19-12-2016, 20:02, Переглядів: 8164